By Franck Pachot
.
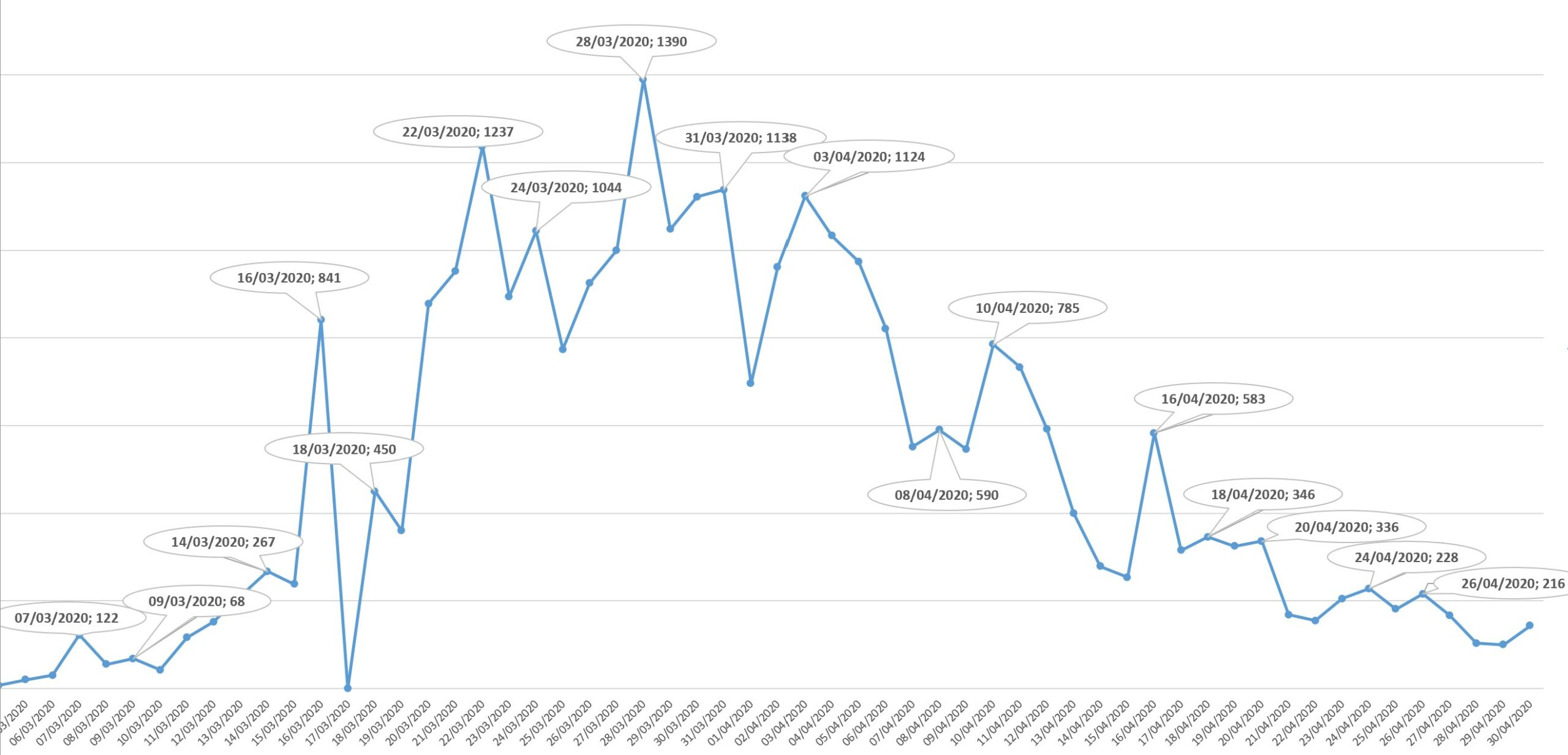
This post is part of a series of small examples of recent features. I’m running this in the Oracle 20c preview in the Oracle Cloud. I have created a few tables in the previous post with a mini-snowflake scheme: a fact table CASES with the covid-19 cases per country and day. And a dimension hierarchy for the country with COUNTRIES and CONTINENTS tables.
This title may look strange for people used to Oracle. I am showing the REFRESH FAST ON STATEMENT Materialized View clause here, also known as “Synchronous Refresh for Materialized Views”. This name makes sense only when you already know materialized views, complete and fast refreshes, on commit and on-demand refreshes… But that’s not what people will look for. Indexes are also refreshed by the statements, synchronously. Imagine that they were called “Synchronous Refresh for B*Trees”, do you think they would have been so popular?
A materialized view, like an index, is a redundant structure where data is stored in a different physical layout in order to be optimal for alternative queries. For example, you ingest data per date (which is the case in my covid-19 table – each day a new row with the covid-19 cases per country). But if I want to query all points for a specific country, those are scattered though the physical segment that is behind the table (or the partition). With an index on the country_code, I can identify easily one country, because the index is sorted on the country. I may need to go to the table to get the rows, and that is expensive, but I can avoid it by adding all the attributes in the index. With Oracle, as with many databases, we can build covering indexes, for real index-only access, even if they don’t mention those names.
But with my snowflake schema, I’ll not have the country_code in the fact table and I have to join to a dimension. This is more expensive because the index on the country_name will get the country_id and then I have to go to an index on the fact table to get the rows for this country_id. When it comes to joins, I cannot index the result of the join (I’m skipping bitmap join indexes here because I’m talking about covering indexes). What I would like is an index with values from multiple tables.
A materialized view can achieve much more than an index. We can build the result of the join in one table. And no need for event sourcing or streaming here to keep it up to date. No need to denormalize and risk inconsistency. When NoSQL pioneers tell you that storage is cheap and redundancy is the way to scale, just keep your relational database for integrity and build materialized views on top. When they tell you that joins are expensive, just materialize them upfront. Before 12c, keeping those materialized views consistent with the source required either:
- materialized view logs which is similar to event sourcing except that ON COMMIT refresh is strongly consistent
- partition change tracking which is ok for bulk changes, when scaling big data
This is different from indexes which are maintained immediately: when you update the row, the index is synchronized because your session has the values and the rowid and can go directly to update the index entry.
refresh fast on statement
In 12c you have the benefit from both: index-like fast maintenance with rowid access, and the MView possibility of querying pre-build joins. Here is an example on the tables created in the previous post.
SQL>
create materialized view flatview refresh fast on statement as
select daterep,continent_name,country_name,cases from cases join countries using(country_id) join continents
using(continent_id) where cases>0;
select daterep,continent_name,country_name,cases from cases join countries using(country_id) join continents using(continent_id) where cases>0
*
ERROR at line 2:
ORA-12015: cannot create a fast refresh materialized view from a complex query
There are some limitations when we want fast refresh and we have a utility to help us understand what we have to change or add in our select clause.
explain_mview
I need to create the table where the messages will be written to by this utility:
@ ?/rdbms/admin/utlxmv
SQL>
set sqlformat ansiconsole
SQL>
set pagesize 10000
This has created mv_capabilities_table and I can run dbms_mview.explain_mview() now.
Here is the call, with the select part of the materialized view:
SQL>
exec dbms_mview.explain_mview('-
select daterep,continent_name,country_name,cases from cases join countries using(country_id) join continents using(continent_id) where cases>0-
');
PL/SQL procedure successfully completed.
SQL>
select possible "?",capability_name,related_text,msgtxt from mv_capabilities_table where capability_name like 'REFRESH_FAST%' order by seq;
? CAPABILITY_NAME RELATED_TEXT MSGTXT
____ ________________________________ _______________ ______________________________________________________________________
N REFRESH_FAST
N REFRESH_FAST_AFTER_INSERT inline view or subquery in FROM list not supported for this type MV
N REFRESH_FAST_AFTER_INSERT inline view or subquery in FROM list not supported for this type MV
N REFRESH_FAST_AFTER_INSERT view or subquery in from list
N REFRESH_FAST_AFTER_ONETAB_DML see the reason why REFRESH_FAST_AFTER_INSERT is disabled
N REFRESH_FAST_AFTER_ANY_DML see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled
N REFRESH_FAST_PCT PCT FAST REFRESH is not possible if query contains an inline view
SQL>
rollback;
Rollback complete.
“inline view or subquery in FROM list not supported for this type MV” is actually very misleading. I use ANSI joins and they are translated to query blocks and this is not supported.
No ANSI joins
I rewrite it with the old join syntax:
SQL>
exec dbms_mview.explain_mview('-
select daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0-
');
PL/SQL procedure successfully completed.
SQL>
select possible "?",capability_name,related_text,msgtxt from mv_capabilities_table where capability_name like 'REFRESH_FAST%' order by seq;
? CAPABILITY_NAME RELATED_TEXT MSGTXT
____ ________________________________ __________________ ___________________________________________________________________________
N REFRESH_FAST
N REFRESH_FAST_AFTER_INSERT CONTINENTS the SELECT list does not have the rowids of all the detail tables
N REFRESH_FAST_AFTER_INSERT DEMO.CASES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.COUNTRIES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.CONTINENTS the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_ONETAB_DML see the reason why REFRESH_FAST_AFTER_INSERT is disabled
N REFRESH_FAST_AFTER_ANY_DML see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled
N REFRESH_FAST_PCT PCT is not possible on any of the detail tables in the materialized view
SQL>
rollback;
Rollback complete.
Now I need to add the ROWID of the table CONTINENTS in the materialized view.
ROWID for all tables
Yes, as I mentioned, the gap between indexes and materialized views is shorter. The REFRESH FAST ON STATEMENT requires access by rowid to update the materialized view, like when a statement updates an index.
SQL>
exec dbms_mview.explain_mview('-
select continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0-
');
PL/SQL procedure successfully completed.
SQL>
select possible "?",capability_name,related_text,msgtxt from mv_capabilities_table where capability_name like 'REFRESH_FAST%' order by seq;
? CAPABILITY_NAME RELATED_TEXT MSGTXT
____ ________________________________ __________________ ___________________________________________________________________________
N REFRESH_FAST
N REFRESH_FAST_AFTER_INSERT COUNTRIES the SELECT list does not have the rowids of all the detail tables
N REFRESH_FAST_AFTER_INSERT DEMO.CASES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.COUNTRIES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.CONTINENTS the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_ONETAB_DML see the reason why REFRESH_FAST_AFTER_INSERT is disabled
N REFRESH_FAST_AFTER_ANY_DML see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled
N REFRESH_FAST_PCT PCT is not possible on any of the detail tables in the materialized view
SQL>
rollback;
Rollback complete.
Now, the ROWID for COUNTRIES.
I continue the and finally I’ve added ROWID for all tables involved:
SQL>
exec dbms_mview.explain_mview('-
select continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0-
');
PL/SQL procedure successfully completed.
SQL>
select possible "?",capability_name,related_text,msgtxt from mv_capabilities_table where capability_name like 'REFRESH_FAST%' order by seq;
? CAPABILITY_NAME RELATED_TEXT MSGTXT
____ ________________________________ __________________ ___________________________________________________________________________
N REFRESH_FAST
N REFRESH_FAST_AFTER_INSERT COUNTRIES the SELECT list does not have the rowids of all the detail tables
N REFRESH_FAST_AFTER_INSERT DEMO.CASES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.COUNTRIES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.CONTINENTS the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_ONETAB_DML see the reason why REFRESH_FAST_AFTER_INSERT is disabled
N REFRESH_FAST_AFTER_ANY_DML see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled
N REFRESH_FAST_PCT PCT is not possible on any of the detail tables in the materialized view
SQL>
rollback;
Rollback complete.
SQL>
exec dbms_mview.explain_mview('-
select cases.rowid case_rowid,countries.rowid country_rowid,continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0-
');
PL/SQL procedure successfully completed.
SQL> select possible "?",capability_name,related_text,msgtxt from mv_capabilities_table where capability_name like 'REFRESH_FAST%' order by seq;
? CAPABILITY_NAME RELATED_TEXT MSGTXT
____ ________________________________ __________________ ___________________________________________________________________________
N REFRESH_FAST
N REFRESH_FAST_AFTER_INSERT DEMO.CASES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.COUNTRIES the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_INSERT DEMO.CONTINENTS the detail table does not have a materialized view log
N REFRESH_FAST_AFTER_ONETAB_DML see the reason why REFRESH_FAST_AFTER_INSERT is disabled
N REFRESH_FAST_AFTER_ANY_DML see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled
N REFRESH_FAST_PCT PCT is not possible on any of the detail tables in the materialized view
SQL>
rollback;
Rollback complete.
Ok, now another message: “the detail table does not have a materialized view log”. But that’s exactly the purpose of statement-level refresh: being able to fast refresh without creating and maintaining materialized view logs, and without full-refreshing a table or a partition.
This’t the limit of DBMS_MVIEW.EXPLAIN_MVIEW. Let’s try to create the materialized view now:
SQL>
create materialized view flatview refresh fast on statement as
select cases.rowid case_rowid,countries.rowid country_rowid,continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0;
select cases.rowid case_rowid,countries.rowid country_rowid,continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0
*
ERROR at line 2:
ORA-32428: on-statement materialized join view error: Shape of MV is not
supported(composite PK)
SQL>
That’s clear. I had created the fact primary key on the compound foreign keys.
Surrogate key on fact table
This is not allowed by statement-level refresh, so let’s change that:
SQL>
alter table cases add (case_id number);
Table altered.
SQL>
update cases set case_id=rownum;
21274 rows updated.
SQL>
alter table cases drop primary key;
Table altered.
SQL>
alter table cases add primary key(case_id);
Table altered.
SQL>
alter table cases add unique(daterep,country_id);
Table altered.
I have added a surrogate key and defined a unique key for the composite one.
Now the creation is sucessful:
SQL>
create materialized view flatview refresh fast on statement as
select cases.rowid case_rowid,countries.rowid country_rowid,continents.rowid continent_rowid,daterep,continent_name,country_name,cases from cases , countries , continents where cases.country_id=countries.country_id and countries.continent_id=continents.continent_id and cases>0;
Materialized view created.
Note that I tested later and I am able to create it with the ROWID from the fact table CASES only. But that’s not a good idea: in order to propagate any change to the underlying tables, the materialized view must have the ROWID, like an index. I consider as a bug the possibility to do it.
Here are the columns stored in my materialized view:
SQL>
desc flatview
Name Null? Type
__________________ ________ _______________
CASE_ROWID ROWID
COUNTRY_ROWID ROWID
CONTINENT_ROWID ROWID
DATEREP VARCHAR2(10)
CONTINENT_NAME VARCHAR2(30)
COUNTRY_NAME VARCHAR2(60)
CASES NUMBER
Storing the ROWID is not something we should recommend as some maintenance operations may change the physical location of rows. You will need to complete refresh the materialized view after an online move for example.
No-join query
I’ll show query rewrite in another blog post. For the moment, I’ll query this materialized view directly.
Here is a query similar to the one in the previous post:
SQL>
select continent_name,country_name,top_date,top_cases from (
select continent_name,country_name,daterep,cases
,first_value(daterep)over(partition by continent_name order by cases desc) top_date
,first_value(cases)over(partition by continent_name order by cases desc)top_cases
,row_number()over(partition by continent_name order by cases desc) r
from flatview
)
where r=1 order by top_cases
;
CONTINENT_NAME COUNTRY_NAME TOP_DATE TOP_CASES
_________________ ___________________________ _____________ ____________
Oceania Australia 23/03/2020 611
Africa South_Africa 05/06/2020 3267
Europe Russia 12/05/2020 11656
Asia China 13/02/2020 15141
America United_States_of_America 26/04/2020 48529
I have replaced the country_id and continent_id by their name as I didn’t put them in my materialized view. And I repeated the window function everywhere if you want to run the same in versions lower than 20c.
This materialized view is a table. I can partition it by hash to scatter the data. I can cluster on another column. I can add indexes. I have the full power of a SQL databases on it, without the need to join if you think that joins are slow. If you come from NoSQL you can see it like a DynamoDB global index. You can query it without joining, fetching all attributes with one call, and filtering on another key than the primary key. But here we have always strong consistency: the changes are replicated immediately, fully ACID. They will be committed or rolled back by the same transaction that did the change. They will be replicated synchronously or asynchronously with read-only replicas.
DML on base tables
Let’s do some changes here, lowering the covid-19 cases of CHN to 42%:
SQL>
alter session set sql_trace=true;
Session altered.
SQL>
update cases set cases=cases*0.42 where country_id=(select country_id from countries where country_code='CHN');
157 rows updated.
SQL>
alter session set sql_trace=false;
Session altered.
I have set sql_trace because I want to have a look at the magic behind it.
Now running my query on the materialized view:
SQL>
select continent_name,country_name,top_date,top_cases from (
select continent_name,country_name,daterep,cases
,first_value(daterep)over(partition by continent_name order by cases desc) top_date
,first_value(cases)over(partition by continent_name order by cases desc)top_cases
,row_number()over(partition by continent_name order by cases desc) r
from flatview
)
where r=1 order by top_cases
;
CONTINENT_NAME COUNTRY_NAME TOP_DATE TOP_CASES
_________________ ___________________________ _____________ ____________
Oceania Australia 23/03/2020 611
Africa South_Africa 05/06/2020 3267
Asia India 05/06/2020 9851
Europe Russia 12/05/2020 11656
America United_States_of_America 26/04/2020 48529
CHN is not the top one in Asia anymore with the 42% correction.
The changes were immediately propagated to the materialized view like when indexes are updated, and we can see that in the trace:
SQL>
column value new_value tracefile
SQL>
select value from v$diag_info where name='Default Trace File';
VALUE
__________________________________________________________________________
/u01/app/oracle/diag/rdbms/cdb1a_iad154/CDB1A/trace/CDB1A_ora_49139.trc
SQL>
column value clear
SQL>
host tkprof &tracefile trace.txt
TKPROF: Release 20.0.0.0.0 - Development on Thu Jun 4 15:43:13 2020
Copyright (c) 1982, 2020, Oracle and/or its affiliates. All rights reserved.
SQL>
host awk '/"FLATVIEW/,/^[*]/' trace.txt
sql_trace instruments all executions with time and number of rows. tkprof aggregates those for analysis.
The trace shows two statements on my materialized view: DELETE and INSERT.
The first one is about removing the modified rows.
DELETE FROM "DEMO"."FLATVIEW"
WHERE
"CASE_ROWID" = :1
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 158 0.00 0.00 0 0 0 0
Execute 158 0.02 0.10 38 316 438 142
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 316 0.02 0.10 38 316 438 142
Misses in library cache during parse: 1
Misses in library cache during execute: 1
Optimizer mode: ALL_ROWS
Parsing user id: 634 (recursive depth: 1)
Number of plan statistics captured: 3
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
0 0 0 DELETE FLATVIEW (cr=2 pr=0 pw=0 time=2080 us starts=1)
1 0 1 INDEX UNIQUE SCAN I_OS$_FLATVIEW (cr=2 pr=0 pw=0 time=2055 us starts=1 cost=1 size=10 card=1)(object id 78728)
This has been done row-by-row but is optimized with an index on ROWID that has been created autonomously with my materialized view.
The second one is inserting the modified rows:
INSERT INTO "DEMO"."FLATVIEW" SELECT "CASES".ROWID "CASE_ROWID",
"COUNTRIES".ROWID "COUNTRY_ROWID","CONTINENTS".ROWID "CONTINENT_ROWID",
"CASES"."DATEREP" "DATEREP","CONTINENTS"."CONTINENT_NAME" "CONTINENT_NAME",
"COUNTRIES"."COUNTRY_NAME" "COUNTRY_NAME","CASES"."CASES" "CASES" FROM
"CONTINENTS" "CONTINENTS","COUNTRIES" "COUNTRIES", (SELECT "CASES".ROWID
"ROWID","CASES"."DATEREP" "DATEREP","CASES"."CASES" "CASES",
"CASES"."COUNTRY_ID" "COUNTRY_ID" FROM "DEMO"."CASES" "CASES" WHERE
"CASES".ROWID=(:Z)) "CASES" WHERE "CASES"."COUNTRY_ID"=
"COUNTRIES"."COUNTRY_ID" AND "COUNTRIES"."CONTINENT_ID"=
"CONTINENTS"."CONTINENT_ID" AND "CASES"."CASES">0
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 158 0.00 0.00 0 0 0 0
Execute 158 0.01 0.11 0 734 616 142
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 316 0.02 0.12 0 734 616 142
Misses in library cache during parse: 1
Misses in library cache during execute: 1
Optimizer mode: ALL_ROWS
Parsing user id: 634 (recursive depth: 1)
Number of plan statistics captured: 3
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
0 0 0 LOAD TABLE CONVENTIONAL FLATVIEW (cr=5 pr=0 pw=0 time=235 us starts=1)
1 0 1 NESTED LOOPS (cr=2 pr=0 pw=0 time=25 us starts=1 cost=3 size=52 card=1)
1 0 1 NESTED LOOPS (cr=2 pr=0 pw=0 time=20 us starts=1 cost=2 size=42 card=1)
1 0 1 TABLE ACCESS BY USER ROWID CASES (cr=1 pr=0 pw=0 time=14 us starts=1 cost=1 size=22 card=1)
1 0 1 TABLE ACCESS BY INDEX ROWID COUNTRIES (cr=1 pr=0 pw=0 time=5 us starts=1 cost=1 size=20 card=1)
1 0 1 INDEX UNIQUE SCAN SYS_C009414 (cr=0 pr=0 pw=0 time=3 us starts=1 cost=0 size=0 card=1)(object id 78716)
1 0 1 TABLE ACCESS BY INDEX ROWID CONTINENTS (cr=1 pr=0 pw=0 time=2 us starts=1 cost=1 size=10 card=1)
1 0 1 INDEX UNIQUE SCAN SYS_C009412 (cr=0 pr=0 pw=0 time=1 us starts=1 cost=0 size=0 card=1)(object id 78715)
Again, a row-by-row insert apparently as the “execute count” is nearly the same as the “rows count”. 157 is the number of rows I have updated.
You may think that this is a huge overhead, but those operations are optimized for a long time. The materialized view is refreshed and ready for optimal queries: no need to queue, stream, reorg, vacuum,… And I can imagine that if this feature is used, it will be optimized with bulk operations which would allow compression.
Truncate
This looks all good. But… what happens if I truncate the table?
SQL>
truncate table cases;
Table truncated.
SQL>
select continent_name,country_name,top_date,top_cases from (
select continent_name,country_name,daterep,cases
,first_value(daterep)over(partition by continent_name order by cases desc) top_date
,first_value(cases)over(partition by continent_name order by cases desc)top_cases
,row_number()over(partition by continent_name order by cases desc) r
from flatview
)
where r=1 order by top_cases
;
CONTINENT_NAME COUNTRY_NAME TOP_DATE TOP_CASES
_________________ ___________________________ _____________ ____________
Oceania Australia 23/03/2020 611
Africa South_Africa 05/06/2020 3267
Asia India 05/06/2020 9851
Europe Russia 12/05/2020 11656
America United_States_of_America 26/04/2020 48529
Nothing changed. This is dangerous. You need to refresh it yourself. This may be a bug. What will happen if you insert data back? Note that, like with triggers, direct-path inserts will be transparently run as conventional inserts.
SQL>
exec dbms_mview.refresh('DEMO.FLATVIEW');
SQL>
insert into cases select rownum cases_id,daterep, geoid country_id,cases from covid where continentexp!='Other';
21483 rows created.
SQL>
commit;
CONTINENT_NAME COUNTRY_NAME TOP_DATE TOP_CASES
_________________ ___________________________ _____________ ____________
Oceania Australia 23/03/2020 611
Africa South_Africa 05/06/2020 3267
Europe Russia 12/05/2020 11656
Asia China 13/02/2020 15141
America United_States_of_America 26/04/2020 48529
Joins are not expensive
This feature is really good to pre-build the joins in a composition of tables, as a hierarchical key-value, or snowflake dimension fact table. You can partition, compress, order, filter, index,… as with any relational table. There no risk here with the denormalization as it is transparently maintained when you update the underlying tables.
If you develop on a NoSQL database because you have heard that normalization was invented to reduce storage, which is not nexpensive anymore, that’s a myth (you can read this long thread to understand the origin of this myth). Normalization is about database integrity and separation lof logical and physical layers. And that’s what Oracle Database implements with this feature: you update the logical view, tables are normalized for integrity, and the physical layer transparently maintains additional structures like indexes and materialized views to keep queries under single-digit milliseconds. Today you still need to think about indexes and materialized views to build. Some advisors may help. All those are the bricks for the future: an autonomous database where you define only the logical layer for your application and all those optimisations will be done in background.
L’article Oracle 12c – pre-built join index est apparu en premier sur dbi Blog.